RaspberryPiクラスタ製作記 第4回「BareMetal並列計算」
最終回 BareMetal環境で並列計算をしてみよう

前回はOSの実行にかかるコストを削減するため、BareMetal環境で開発を行いましたが、実行時間はLinux上での結果に負けてしまいました。悔しいです。何とかしてリベンジできないでしょうか。
前回を思い返してみると、Linux上でmpichを用いてLU分解を並列化した結果は、ノード数を増やせば増やすほど通信コストの増加により実行時間は長くなっていました。 ということは、BareMetal環境を活かして通信コストを削減できれば、並列計算時の実行時間は勝てるかもしれません。
そこで今回は、このアイデアを実行し、リベンジを図りたいと思います。また、本連載は今回が最後なので、 記事の終わりに今までの振り返りと要点をまとめます。
通信コスト削減による高速化
冒頭のマンガで述べられているように、BareMetal環境は何もないので、 Ethernetを用いたネットワーク通信を行うには、 LANコントローラのドライバを書き、TCP/IPプロトコルスタックを実装しなければなりません。 この作業を行うとそれだけで1冊本が書けてしまうので、今回はもっと簡単な通信を用います(この後マンガの主人公は、チップの仕様書とUSBの規格書、TCP/IPプロトコルの解説書とにらめっこする日々を過ごすことになるでしょう)。
一般にBareMetal環境やマイコンなどで用いられる通信方法には、以下の3つがあります。
・UART
・SPI
・I2C
これら全てに共通するのは、通信仕様がUSBなどに比べ非常に簡単であり扱いやすく、通信にかかるコストが非常に少ない点です。 この点を活かせば、BareMetal環境上で通信コストを削減した並列計算が行えるはずです。
Raspberry PiのSoCに実装されている中で、最も速度の出る通信方式はSPI(Serial Peripheral Interface)です。 SPIは親(Master)と子(Slave)という役割に分かれ、4本の線を用いて行うシリアル通信です。
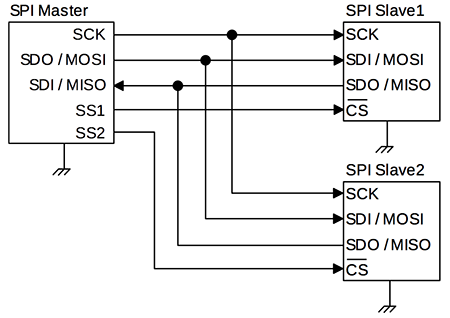
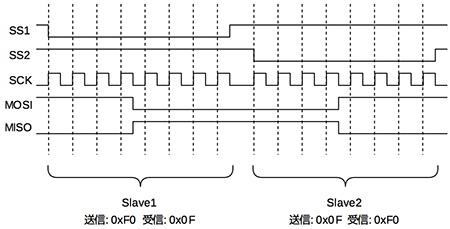
通信は、マスターからスレーブセレクト線(SS)で選択されたスレーブのみが、クロック線(SCLK)から供給されるクロックに合わせて、1bitずつデータの送受信を行います。
SPIの通信クロック(SCLK)は、ペリフェラルマニュアルの156ページより、
SCLK = Core Clock(default: 250MHz) / CDIV(=2^n) # ただしn=0の場合はCDIV=65536
で計算されるので、n=1の場合に最大の125MHz、つまり理論的には最大125Mbpsで通信が行えます。
しかし、私がRaspberry Pi同士のSPI通信を試したところ、Slave側がうまく動作せず、通信できませんでした。問題解決のため、配線、マスタ側からの出力、Slave側のGPIO設定、SPI Slaveレジスタ設定などの確認を行いましたが問題はなく、加えて受信処理プログラムのミスを確認するためSPI Slaveテストレジスタを用いたテスト通信を行いましたが、こちらも問題なく動作しました。つまり、Slave側でIOポートを通した通信を受信することができていないようですが、今のところ私にはなぜうまくいかないのかわかりません。この問題については引き続き調査を続けますが、記事の締め切りがあるため今回は別の方法を用いることにしました。
2番目に高速なのはUART(Universal Asynchronous Receiver Transmitter)です。 これは通常9600 baudや115200 baud程度の低いボーレート(1秒間に行われる変復調の回数)で、パソコンやマイコン間で文字列を送受信するために使われていますが、設定を変更することでボーレートをMbaudまで上げた高速通信が可能です。
代わりにSPIと違い、基本は1対1での通信しか行えません。 この点は非常に残念ですが、ほかに高速で簡単に扱えるものが見つからないためBareMetal環境の通信はUARTを用いて行います。
Ethernet&TCP/IP vs UART
BareMetal環境の通信にはUARTを用いることにしましたが、 理論的にはEthernet&TCP/IPと比べてどれだけ速くなるか気になります。
そこで、ここではEthernet&TCP/IPとUART&独自プロトコルの速度を調べて比較します。
Ethernet&TCP/IP
ご存知のように、ネットワーク通信は送受信するデータを細かく分けたパケットという単位で行います。 このパケットは入れ子構造になっており、例えばTCP通信のパケットは、Ethernet, IP, TCPパケットに包まれた3重構造になっています。
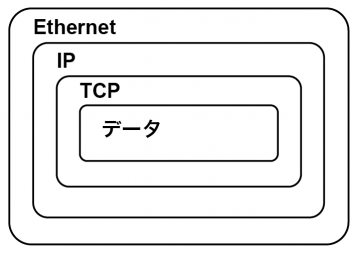
各パケットには宛先などの情報が記されたヘッダがついており、Ethernet、IP、TCPパケットのヘッダを合わせると、長さは66byteになります(オプションなしの場合)。 一番外殻であるEthernetパケットの長さは最大で1526byteなので、 Ethernetを用いた通信は、データ1460byteにつき66byteのオーバーヘッドが発生します。 このオーバーヘッドを考慮して最大通信速度を考えると、100Mbps * 0.96 = 96Mbpsとなります。
UART
Raspberry PiのUARTのボーレートは、ペリフェラルマニュアルの183ページより、次の計算式で求められます。
baudrate = F_UARTCLK(default: 3MHz) / (16 * BAUDDIV)
この計算式のうち、F_UARTCLKとBAUDDIVは変更可能であり、前者は起動スクリプトを修正、後者はレジスタの設定を行うことで変更できます。
F_UARTCLKは通常3MHzとなっていますが、SDカードの第1パーティションにあるconfig.txtに次の一文を追記すると変更できます。
init_uart_clock=416000000
ここに設定する値は、Raspberry PiのSoCが搭載しているUARTペリフェラル(PL011)マニュアルによると、Core Clock(250Mhz)* 5/3 までの値が推奨されているので、F_UARTCLKは416MHzが最大となります。
BAUDDIVはIBRDとFBRDレジスタで設定でき、 どちらも0にした場合にBAUDDIV=1となり、 最大ボーレートは以下の計算式より26Mbaudとなります。
baudrate = 416(MHz) / (16 * 1) = 26(Mbaud)
UARTは1度に1bitの変復調を行うので、通信速度の最大は26Mbpsとなります。
実際に設定してオシロスコープで見てみると、確かに26MHzの波形が出ていることが確認できます。
UARTの通信は8bitずつ行われ、データの開始と終了を判定するためにスタートビットとストップビットが最小で1bitずつ付きます。
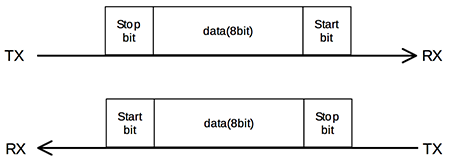
つまり、8bitあたり2bitのオーバーヘッドが発生するので、これを考慮した最大通信速度は 26Mbps * 0.8 = 20.8Mbpsとなります。
Ethernet&TCP/IPとUARTの比較
以上で述べた、EthernetとUART通信のオーバーヘッドを含めた最大速度を以下に示します。
| 通信方式 | 最大通信速度(Mbps) |
|---|---|
| Ethernet&TCP/IP | 96 |
| UART | 20.8 |
この結果はEthernetの圧倒的勝利のように見えます。しかし、現在考慮しているEthernet&TCP/IPのオーバーヘッドはトランスポート層までであり、セッション層以降のオーバーヘッドについては考慮していません。 つまり、セッション層以上にまだまだ多くのオーバーヘッドが存在するはずです。 対するUARTは1対1通信のため送信先選択などを行う必要がなく、オーバーヘッドは少なくなるはずです。 この差を考慮すれば、もしかするとUARTを用いた並列計算のほうが速くなるかもしれません。
まだ希望はあるはずです。 やって確かめてみましょう。
ソフトウェアの実装
UARTは1対1通信なので、前回作成した並列計算プログラムをノード数2に限定し、行列Aを2つに分けた前半を処理するノード0と、後半を処理するノード1のコードを作ります。
MPI関数を用いて行っていた枢軸ベクトルや計算後のLU行列の転送は、以下のUART通信を用いた関数に置き換えて行います。
void Serial_send(uint8_t *buf, int len) 第1引数bufで指定されたアドレスから第2引数len(byte)データを送信する
void Serial_receive(uint8_t *buf, int len) 第1引数bufで指定されたアドレスから第2引数len(byte)データを受信する
void uart0_putc(int c) 第1引数cで指定された値の下位8bitを送信する
int uart0_putc() 受信した8bitの値を返す
この変更を行ったコードをこちらで何度か動かしたところ、UARTで10byte程度以上の連続通信を行うと、データの整合がとれなくなる問題が発生しました。そのため、データの転送は4byte(double型の1つ分)ごとに 開始文字’s’と終了文字’e’を互いに送り合い、同期を取るようにします。
以上を行ったコードが以下の2つになります。
baremetalLU_node0.zip
baremetalLU_node1.zip
今回は通信にUARTを用いるため、UARTを用いた計算結果や実行時間の出力が行えません。そこで出力はSPI通信で別のマイコンに転送し、そのマイコン経由でパソコンに表示します。
マイコンには開発の容易さからmbed LPC11U24を用います。マイコンのソースコードは以下からダウンロードして使用してください。
なお、mbed LPC11U24のボーレートは115200bpsに設定しています。
ハードウェアの接続
データの通信を行うUARTと、結果の出力を行うmbed LPC11U24の接続を以下に示します。
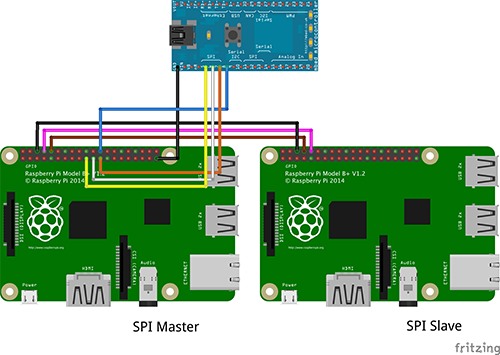
この図を参考に配線を行ってください。
なお、ログ出力用のマイコンはUSBケーブルを用いてパソコンと接続してください。
動作比較
プログラムのコンパイルを行い、出てきたバイナリをRaspberry Piにセットし、電源を入れるとプログラムが動作します。果たして、通信にUARTを用いた結果、通信コストの削減とそれにともなう処理の高速化はできたのでしょうか。以下に結果を示します。
exec time: 6278386
結果は6278ミリ秒。
Linux上で2ノード並列計算を行った際の結果は1600ミリ秒程度だったので、約4倍も遅くなってしまいました。通信速度で既に大きな差があった上に、データの同期を取るため8byteにつき2byteの大きなオーバーヘッドを作ってしまったことが敗因でしょう。
結局、私によるBareMetalの挑戦は残念な結果に終わりました。
もちろん、Linuxも同じRaspberry Piで動いているのですから、同じ設定をハードウェアに行えば、BareMetal環境でも同等かそれ以上の性能が得られるでしょう。しかし、そのためにはより多くの時間と労力が必要になり、難しいです。
片桐さんの著書「スパコンプログラミング入門 並列処理とMPIの学習」の35ページには、次のように書かれています。
「実装する処理によっては,スパコンのメーカー製やフリーソフトウェアによる数値計算ライブラリが利用できることがあります.この場合は,自らプログラミングするのではなく,提供されている数値計算ライブラリを利用する方が,性能が格段に良いことが多いです.〜中略〜最適化されたBLASの性能は,個人で開発した行列と行列の積に対して,10倍以上高速であることも珍しくありません」
私の挑戦が失敗したことからわかるように、既存のOSや計算ライブラリは既に高度な最適化を施されており、高速に動作します。そのため、計算処理の高速化は既存のOSや計算ライブラリを基にチューニングを行うほうが、手軽に期待する性能が得られるでしょう。しかし、そのチューニングのためには、ハードウェアやCPUアーキテクチャについての知識が必要となります。BareMetal開発はこの知識を得るために行い、そこで得た知識を既存のものに対し適応するという手法が良いのではと考えます。
連載のまとめ
本連載は今回が最後なので、今までのまとめとふりかえりを行います。
第0回
第0回では、
・そもそもスパコンとはなにか
・スパコンで計算される問題は本当にスパコンを用いる必要があるのか
を確認するため、現在の一般的なパソコンとスパコン「京」の性能を比べ、 実際に「京」で使われているPHASE0というプログラムを動かして、 実行時間が指数関数的に増えていく様子をグラフで確認しました。
現在はパソコンの性能が上がり、以前はスパコンを用いていた計算も、パソコンで行えるようになりました。 そのため、大学でコンピュータを学んでいる人の中でも、実際にスパコンに触れられる方は少なく、 スパコンとはなにか、何故必要なのかがわからない方もいるのではと感じています。 しかし、調べてみるとスパコンが必要となる計算は確かに存在し、 それらは私たちの生活に深く関わっています。 それを少しでも感じていただけたなら幸いです。
第1回
第1回では、
・クラスタとはなにか
・自作スパコンの作り方
について説明しました。
現代のスパコンは、複数のマシンをつなげてクラスタを作り、高い性能を得ています。 この「クラスタマシンを作る」というと、実用重視で高性能高価格なマシンを繋いだものを想像し、個人では手を出せないと考えてしまうかもしれません。 しかし、勉強のためと割り切って考えれば性能は必要なく、今回のように安価なRaspberry Piを使って作ることも可能です。
また、今回は16台でクラスタマシンの制作を行いましたが、 並列計算の学習を行うだけであれば4台もあれば十分でしょう。 そうすると、コストは1/4の3万円程度になるので、手を出しやすいかと思います。
第2回
第2回では、第1回で制作したRaspberry Piスパコンを用いて、
・PAHSE/0の動作確認
・Linpackを用いた性能評価
・スパコン「京」との性能&コスト比較
を行いました。
PAHSE/0 と Linpack、どちらもノード数を増やすごとに処理速度は上がりましたが、その伸びは非常に悪くなっていきました。 ノード数(プロセッサ)と処理速度の関係には「アムダールの法則」という法則があり、 この法則よりノード数を増やせば増やすほど並列処理に含まれる並列化できない部分がネックになり、 速度の向上の伸びは非常に悪くなっていくことが示されます。
第3回
これまでは既存のソフトウェアを用いて性能評価などを行いましたが、 第3回では実際に自分でMPIを用いて並列処理を書いてみました。
これまでのPHASE/0とLinpackを実行した結果は、プログラムの並列化を行えば(伸びが悪くなることはあっても)必ず高速化されていました。 しかし、自分で並列化したコードはノード数を増やすごとに実行時間が増えるという結果になり、 並列化によりきちんと高速化されるプログラムを作るのは難しいことがわかりました。
今回用いた初代Raspberry PiはCPU性能が低く、並列化のためのコストが結果に大きく響きます。 逆に言えば、正しく効率的な並列化を行った場合のみ性能が向上する素直なマシンであり、 分散メモリ型の並列プログラミングの教材として最適なマシンと言えます。
一方、2015年2月3日に発売された新型のRaspberry Pi 2は、CPUが ARM11 700MHz シングルコア から Cortex-A7 900MHz クアッドコア(4コア)に変更され、性能が大幅に向上しました。発売直後、個人的に購入した1台のRaspberry Pi 2上でコアを4つ用いてLinpackを実行してみたところ、1台で旧型(Raspberry Pi Model B+)6台分の性能が得られました(詳細についてはブログ記事を参照してください)。コアを4つ持っていることを活かして、旧型では行えなかった共有メモリ型の並列プログラミング学習も行えます。
もし今からRaspberry Piスパコンを作るのであれば、 学習の目的に応じて、新型・旧型を使い分ければ良いと思います。
おわりに
本連載を読んでいただき、ありがとうございました。
第0回でも述べたように、 スパコンは私たちの生活をより豊かなものとするため必要不可欠なものです。 スパコンを自作するという本連載を通して、 スパコンの必要性や、高度な技術により支えられていることを感じていただき、 興味を持っていただけたなら幸いです。
最後に、スパコンについてより詳しく知りたい方のため、 本連載を書く際に参考にした書籍をご紹介します。
・絵でわかるスーパーコンピュータ 姫野龍太郎 著 ISBN: 978-4061547643
・スパコンプログラミング入門 片桐孝洋 著 ISBN: 978-4130624534
・スーパーコンピューターを20万円で創る 伊藤智義 著 ISBN: 978-4087203950
・ARMで学ぶ アセンブリ言語入門 出村成和 著 ISBN: 978-4863541269
・ルーター自作でわかるパケットの流れ 小俣光之 著 ISBN: 978-4774147451
著者プロフィール
西永俊文 1992年生まれの情報系大学生。一人前のエンジニアを目指して日々勉強中。PDA全盛期の影響から、組み込み機器が好き。今欲しい物は、現代の技術で作られた物理キーボード付きで4インチ以下の小さなスマートフォン。著書に『BareMetalで遊ぶ Raspberry Pi』がある。
〈四コママンガ:囚〉

連載目次
2014-12-01 RaspberryPiクラスタ製作記 第0回「スパコンって本当にスゴイの?」
2014-12-01 PHASE/0のインストール方法
2014-12-16 RaspberryPiクラスタ製作記 第1回「スパコンを作ろう」
2014-12-16 Raspberry Piの初期設定
2014-12-29 RaspberryPiクラスタ製作記 第2回「スパコンで遊ぼう」
2014-12-29 HPLのインストール方法
2015-02-11 RaspberryPiクラスタ製作記 第3回「並列プログラミング」
2015-02-11 MPIを用いた並列プログラミングの概要
2015-02-11 LU分解アルゴリズムのおさらい
2015-03-01 RaspberryPiクラスタ製作記 第4回「BareMetal並列計算」