RaspberryPiクラスタ製作記 第2回「スパコンで遊ぼう」
第2回 Raspberry Piスパコンで遊ぼう
自作したばかりのスーパコンピュータ上で、 第0回で動かした第一原理電子状態計算ソフトウェアPHASE/0を動かして遊んでみましょう。
この遊びの目的は以下の2つです。
・自作スパコンでも「京」で動いている計算プログラムが動くことを確認する
・並列化により処理がどれだけ高速化されるかを確認する
「並列化により処理がどれだけ高速化されるか」に対して、まずあえてもっとも単純に予想すると「並列計算ノード数を増やすと、それに比例して性能も上昇する」となります。ノード数を倍にするということは計算に使えるリソースが倍になるということなので、ノード数に比例して処理速度も上がっていくのではないでしょうか。この予想が正しいかどうかを、これから検証していきます。
PHASE/0のインストール
今回使用するRaspberry PiはARMアーキテクチャのCPUを搭載しているため、第0回でx86マシン用にコンパイルしたバイナリを実行することができません。 そこで再度ソースコードからのコンパイルを行います。
最初にPAHSE/0のコンパイルと動作に必要なパッケージをインストールします。 以下のコマンドを実行してください。
$ sudo aptitude -y install gfortran mpich2 libc6-dev
PHASE/0のコンパイルは基本的に ./install.sh を実行するだけですが、こちらで試したところ、今回使用したバージョンのインストールスクリプトはRaspbianでは正常に動作しませんでした。そこで、このインストールスクリプトが正常動作する環境(MacOSX)で動作させてコンパイルに必要なMakefileを生成し、これをRaspberry Pi上に持ち込むことでコンパイルを可能としました。このMakefileを以下のURLより取得してください。
取得したMakefileを phase0_2014.03/src_phase/ 以下に置いて、そのディレクトリ上で make コマンドを実行するとコンパイルが開始されます。エラーなくコンパイルが終了すれば、PHASE/0のインストールは完了です。
計算打ち切り時間の書き換え
PHASE/0の入力ファイル中には、計算をどれだけで打ち切るか(cpumax)の設定が書かれています。今回使用するRaspberry Piは第0回で使用したマシンに比べて非常に性能が低いため、デフォルトの打ち切り時間では計算が終了しません。そのためこの設定を修正して、打ち切り時間を延長します。
samples/Si8/input_scf_Si8.data を開いて、以下の3600secとなっている部分を1dayに修正してください。
Control{
# 修正前
cpumax = 3600 sec ! {sec|min|hour|day}
# 修正後
cpumax = 1 day ! {sec|min|hour|day}
condition=initial
}
MPIノードの設定
PHASE/0のプログラムはMPI方式でデータをやり取りする、mpichというアプリケーションを用いて並列計算を行います。 このmpichは、自分のマシンと一緒に計算を行うマシン(ノード)のホストネーム(またはIPアドレス)を設定ファイルに記述し、それを実行時に読み込ませることで並列計算が可能となります。 以下にその設定ファイルを記すので ~/mpdhosts に保存してください。
rpicluster01 rpicluster02 rpicluster03 rpicluster04 rpicluster05 rpicluster06 rpicluster07 rpicluster08 rpicluster09 rpicluster10 rpicluster11 rpicluster12 rpicluster13 rpicluster14 rpicluster15 rpicluster16
処理時間の計測
インストールの終わったPHASE/0を使い、 ノード数を1,4,9,16と変化させて、その処理時間を計測します。
1ノード1並列
最初は動作確認のため1並列で動かしてみましょう。 以下のコマンドで計算を開始してください。
pi@rpicluster01 ~/phase0_2014.02_rpi/samples/Si8 $ time mpirun -f ~/mpihosts -np=1 ../../bin/phase -ne=1 -nk=1 real 32m59.518s user 29m53.770s sys 3m2.960s
実行時間は実時間で約33分と、第0回と比べて非常に時間のかかる結果となりました。 今回使用したRaspberry Piはクロックが700MHzの32bitマシンなので、妥当なスコアでしょう。
4ノード4並列
次にRaspberry Piクラスタマシンのノードを4台使用し、計算を4並列で回してみます。 予想のとおりであれば、CPUの数が4倍になるので実行時間も1/4になるはずですが、果たしてどうなるでしょうか。
pi@rpicluster01 ~/phase0_2014.02_rpi/samples/Si8 $ time mpirun -f ~/mpihosts -np=4 ../../bin/phase -ne=2 -nk=2 real 16m14.437s user 13m50.940s sys 2m20.780s
実行時間は実時間で約16分、1並列の約半分となりました。 1/4とまでは行きませんでしたが、1/2でもまずまずのスコアでしょう。
この調子で9,16並列で計算を行い、その性能の上昇を見ていきます。
9ノード9並列
pi@rpicluster01 ~/phase0_2014.02_rpi/samples/Si8 $ time mpirun -f ~/mpihosts -np=9 ../../bin/phase -ne=3 -nk=3 real 11m22.431s user 9m41.020s sys 1m39.270s
16ノード16並列
pi@rpicluster01 ~/phase0_2014.02_rpi/samples/Si8 $ time mpirun -f ~/mpihosts -np=16 ../../bin/phase -ne=4 -nk=4 real 9m25.834s user 7m11.440s sys 2m11.720s
計算結果の考察
1,4,9,16並列の計算時間の結果をまとめたグラフを示します。
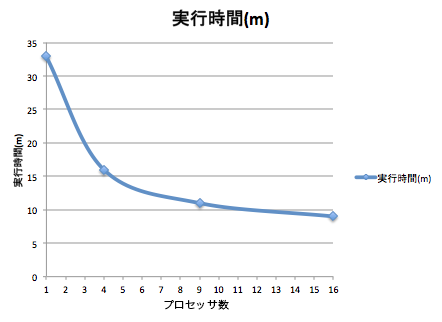
予想ではノード数を上げると計算に使えるCPUの数が増えるので、ノード数に比例して実行時間は減っていくはずでした。 しかし実際は、4並列の時の実行時間は一気に約1/2となったものの、 その後の9並列では1並列に比べ約1/3と伸びが悪くなり、16並列ではより一層伸びが悪くなっています。
一体どうして、計算時間はノード数に比例して下がっていかなかったのでしょうか。
アムダールの法則
計算時間がノード数に比例して下がらない理由ついて、第1回と同じように夏休みの宿題にたとえて説明します。 第1回では、夏休みの宿題として計算問題を100題だされたとしても、 100人の協力者が1問づつ解いて最後に答えを共有すれば、一瞬で解くことができると言っていました。 この計算問題を100人で解く手順を改めて示すと、以下の5手順に分けられます。
1.計算を100個に分割する
2.分けた計算を担当する協力者に解いてもらうよう指示を出す
3.それぞれ協力者が計算する
4.結果を集める
5.結果を問題集に書き込む
こうしてみると、100人の協力者が同時に作業を行える部分、つまり並列処理できる部分は手順3.だけです。 それ以外の部分は指示を出す人が1人で行う必要がある部分、つまり並列処理することができない部分です。
この例からわかるように、処理の中には並列に処理することにより高速化できる部分と、そうでない部分が存在します。 そのためノード数を上げることによる処理時間の減少は、一定のラインを超えると並列処理により高速化できない部分がネックとなり、処理時間の減少の伸びが非常に悪くなります。これが今回私たちの実験で起こった現象です。
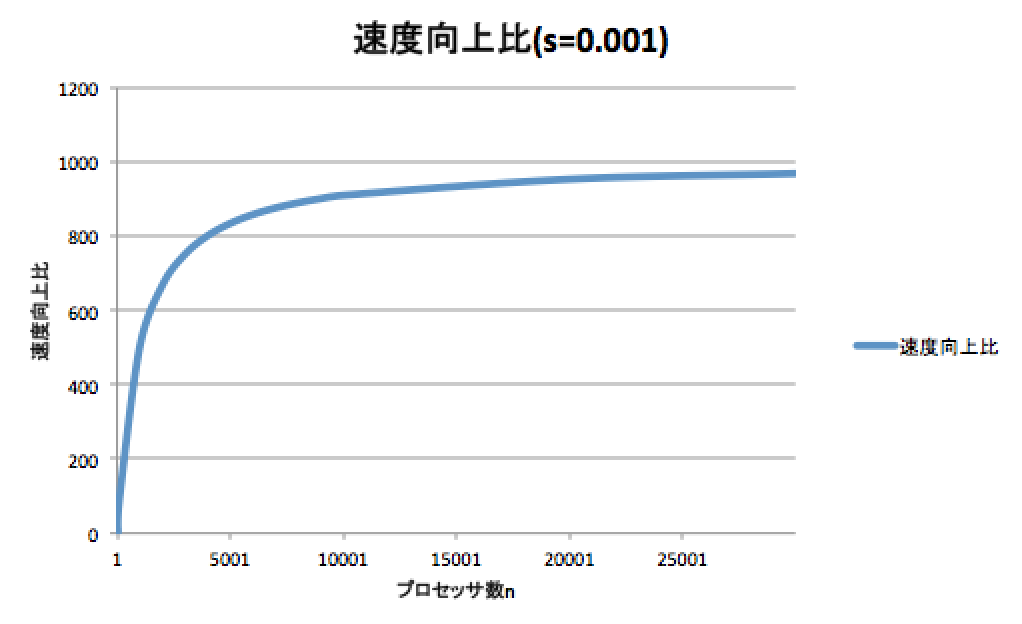
このノード数(プロセッサ)と処理速度の関係には「アムダールの法則」という法則があります。 アムダールの法則は、並列化できない部分の割合をs、プロセッサ数をnとすると、 次の式で処理速度の向上比を計算することができます。

実際にこの式を使い、s=0.001、n=1~30000で計算した結果をグラフに示します。
性能評価とコストの比較
コンピュータの性能には、理論性能と実行性能の2つがあります。
理論性能 ハードウェアの性能から単純に計算した最大性能。例えば700MHzで動作するRaspberry Piは、1クロックで1回浮動小数点演算が行えるので、理論性能700MFLOPSとなる。
実効性能 何らかのベンチマークソフトを動かして得た性能。
理論性能はあくまで理論的な最大性能なので、実効性能とは離れた結果となります。 先ほど私たちの自作スパコン上でPHASE0を動かした結果からもわかると思います。 しかし、具体的にどれだけの性能を持っているかは、まだ調べていませんでした。
性能の他にもうひとつ気になるのは、そのお値段です。現代はコストパフォーマンスを重視する傾向にあります。そのため、どれだけスパコンの性能が良くとも製作費やランニングコストが高すぎては実用的ではありません。
ところで、Raspberry PiのCPUアーキテクチャはARMというものでした。 このARMのCPUは性能に対して消費電力が低いという特徴があり、 身近なところでは携帯ゲーム機やスマートフォンで使用されています。 そのためもしかすると、消費電力――つまりランニングコストの面では、スパコン「京」に勝つことができるのではないでしょうか。
ここからはRaspberry Piスパコンの実効性能とそのコストを調べ、最後にスパコン「京」と比較してみましょう。
実効性能計測
Linpackは、コンピュータの実効性能の計測(ベンチマーク)を行うプログラムのひとつです。 TOP500ではこれを並列化した「HPL」(High-Performance Linpack)を用いて、ベンチマークスコアを測っています。 私たちのRaspberry Piクラスタマシンも、このHPLを用いて実効性能を計ってみましょう。
HPLのインストールについては、別のページで説明します。
HPLは処理する問題サイズ、ブロックサイズ等のパラメータ変更することで最適化を行い、 スコアを上げることができます。 しかし最適なパラメータを探すのは非常に大変なので、今回は私の試した中で一番よいスコアの得られた設定を利用します。
以下のファイルをダウンロードし、~/hpl/Linux_ARM_CBLAS/以下へ上書きコピーしてください。
HPLの実行
実行方法はPHASE0とほとんどおなじですが、 こちらはノードの指定にホストネームを使うとエラーが発生するので、 IPアドレスを使ってノードを指定します。 本環境でのrpicluster01-16のIPアドレスは 192.168.240.101-116なので、16ノード計算を行うため以下のコマンドを実行します。
$ cd ~/hpl/bin/Linux_ARM_CBLAS $ mpirun -np 16 -host 192.168.240.101,192.168.240.102, \ 192.168.240.103,192.168.240.104, \ 192.168.240.105,192.168.240.106, \ 192.168.240.107,192.168.240.108, \ 192.168.240.109,192.168.240.110, \ 192.168.240.111,192.168.240.112, \ 192.168.240.113,192.168.240.114, \ 192.168.240.115,192.168.240.116 \ ./xhpl
ベンチマーク結果
================================================================= T/V N NB P Q Time Gflops ----------------------------------------------------------------- WR11C2R4 25600 96 4 4 4211.62 2.656e+00
HPLの結果は2.656GFLOPSとなりました。このスコアは、今から約30年前の1987年に発表されたスパコン「HITAC S-810」(最大3GFLOPS)に匹敵するスコアです。
参考URL: http://museum.ipsj.or.jp/computer/super/index.html
当時は巨大なシステムで実現していた性能が、今ではこんな小さなボード16枚で得られてしまいます。 私は当時まだ生まれていませんが、技術の進歩が肌で感じられました。
ここからは自作Raspberry Piクラスタマシンの制作費とランニングコストを調べていきます。
製作費は11万円
今回製作に使用した部品とそのお値段の一覧を示します。 なお、製作の人件費はないものとします。
| 部品 | 数 | 単価(円) |
|---|---|---|
| Raspbebrry Pi TypeB+ | 16 | 3,900 |
| micro SDカード 8GB | 16 | 800 |
| USB-MicroBケーブル | 16 | 600 |
| 2ポートUSB充電器 | 8 | 800 |
| LANケーブル | 16 | 350 |
| 24ポート スイッチングハブ | 1 | 7,800 |
| 9ポート電源タップ | 2 | 1,000 |
| M2.6連結スペーサーネジ | 72 | 10 |
| 小型メタルラック | 1 | 600 |
| 結束バンド | 1 | 100 |
| ファンシー金網 | 1 | 100 |
| 金網用フック付き小物いれ | 1 | 100 |
以上を合計すると、製作にかかったお金の合計は約11万円でした。
電気代(ランニングコスト)
USB充電器(Raspberry Piの外部電源)とUSBケーブルの間に簡易テスターを仕込んで、Raspberry Piクラスタマシンの消費電力を調べます。

結果は1台あたり200mA。Raspberry Piには負荷に応じてクロックを変えるような機能は無いため、ピーク時もこの値です。よって1台あたりの消費電力は 5(V) x 0.2(A) = 1(W)、16台でも16Wです。 その他、スイッチングハブやUSB充電器のロスを含めると、このクラスタマシンの総消費電力は大体20Wとなります。
この消費電力から電気料金を計算すると、1日あたり約10円となります。製作費同様、メンテナンスにかかる人件費は0円とすると、 ランニングコストは1日あたり10円、1年動かし続けても3560円です。
京との比較
比較のため、スパコン「京」のコストについても調べてみましょう。京のコストについての資料としては、平成25年1月に文部科学省からの資料があります。この資料によると、京の制作費は合計793億円(施設建設費用は含めず)、運用費は平成24年のデータで1年あたり97億円です。
ここまで調べたRaspberry Piクラスタと京の制作費を表に示します。
| 実効性能 | 制作費(円) | 運用費(円/年) | |
|---|---|---|---|
| 京 | 10PFLOPS | 793億 | 97億 |
| RasPiクラスタ | 2.656GFLOPS | 11万 | 3560 |
これだけではわかりづらいので、 性能をコスト(製作費+運用費)で割った、1FLOPSあたりのコストを計算して比較します。
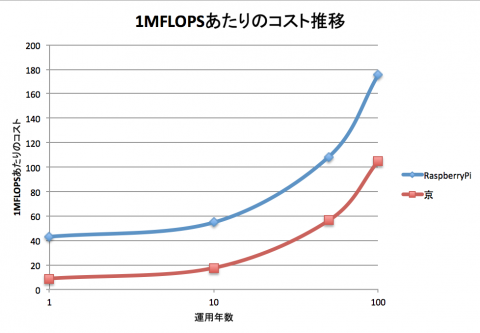
もしかするとコストの面では勝てるのではと考えていましたが、 仮に100年運用したとしても京を追い抜くことはできませんでした。技術の粋を集めて作られた京は、個人のレベルでは到底届かないものであることを再認識することが出来ました。
まとめ
今回はRaspberry Piスパコン制作のソフトウェアの整備と、 その上でPAHSE0の動作を行い、ノード数と計算時間の関係について調べてみました。 この内容を以下に簡単にまとめます。
・ノード数増加による処理速度向上は一定のところで伸び悩む
・アムダールの法則はプロセッサ数と性能向上比の関係を教えてくれる
・京のコストパフォーマンスは自作Raspberry Piスパコンと比べると圧倒的に良い
著者プロフィール
西永俊文 1992年生まれの情報系大学生。一人前のエンジニアを目指して日々勉強中。PDA全盛期の影響から、組み込み機器が好き。今欲しい物は、現代の技術で作られた物理キーボード付きで4インチ以下の小さなスマートフォン。著書に『BareMetalで遊ぶ Raspberry Pi』がある。

連載目次
2014-12-01 RaspberryPiクラスタ製作記 第0回「スパコンって本当にスゴイの?」
2014-12-01 PHASE/0のインストール方法
2014-12-16 RaspberryPiクラスタ製作記 第1回「スパコンを作ろう」
2014-12-16 Raspberry Piの初期設定
2014-12-29 RaspberryPiクラスタ製作記 第2回「スパコンで遊ぼう」
2014-12-29 HPLのインストール方法
2015-02-11 RaspberryPiクラスタ製作記 第3回「並列プログラミング」
2015-02-11 MPIを用いた並列プログラミングの概要
2015-02-11 LU分解アルゴリズムのおさらい
2015-03-01 RaspberryPiクラスタ製作記 第4回「BareMetal並列計算」