京における差分計算の並列処理におけるL1キャッシュ最適化
ソフトウェア
ものづくり > 流体解析 > GT5Dそのほかの分類
高速化手法概要
「京」において多次元領域分割した差分計算を実施する際に、同じノード数を用いても各分割軸の並列数の設定によって処理性能が大幅に変化することがある。ここでは、そのような事例を対象として処理性能が変化する原因を解説し、それを回避する手法を紹介する。
適用事例
プラズマ乱流シミュレーションコードGT5D[1]における4次元差分計算カーネルを対象として問題を議論する。このカーネルは3次元空間および速度空間からなる4次元空間(x,y,z,v)を構造格子で分解し、各方向の移流項を4次精度中心差分(森西スキーム)で計算する。問題規模は(Nx,Ny,Nz,Nv)=(240,240,64,128)とし、これを(x,y)方向に並列度npx×npyで2次元領域分割を行う。このため、1プロセスで担当する領域は(nx,ny,nz,nv)=(Nx/npx,Ny/npy,Nz,Nv)となる。以下に上記カーネルを簡約化したFortranのサンプルコードを示す。
real*8 f(-1:nv+2,-1:nz+2,-1:ny+2,-1:nx+2),df(-1:nv+2,-1:nz+2,-1:ny+2,-1:nx+2)
real*8 vxl(nv),vxr(nv), vyl(nv),vyr(nv), vzl(nv),vzr(nv), vvl(nv),vvr(nv)
real*8 vxl2(nv),vxr2(nv),vyl2(nv),vyr2(nv),vzl2(nv),vzr2(nv),vvl2(nv),vvr2(nv)
:
袖領域データ通信
:
do i = 1,nx
do j = 1,ny
do k = 1,nz
do l = 1,nv
flx = (vxr(l)*(f(l,k,j,i)+f(l,k,j,i+1))-vxl(l)*(f(l,k,j,i)+f(l,k,j,i-1)))*dxi
fly = (vyr(l)*(f(l,k,j,i)+f(l,k,j+1,i))-vyl(l)*(f(l,k,j,i)+f(l,k,j-1,i)))*dyi
flz = (vzr(l)*(f(l,k,j,i)+f(l,k+1,j,i))-vzl(l)*(f(l,k,j,i)+f(l,k-1,j,i)))*dzi
flv = (vvr(l)*(f(l,k,j,i)+f(l+1,k,j,i))-vvl(l)*(f(l,k,j,i)+f(l-1,k,j,i)))*dvi
flx2 = (vxr2(l)*(f(l,k,j,i)+f(l,k,j,i+2))-vxl2(l)*(f(l,k,j,i)+f(l,k,j,i-2)))*dx2i
fly2 = (vyr2(l)*(f(l,k,j,i)+f(l,k,j+2,i))-vyl2(l)*(f(l,k,j,i)+f(l,k,j-2,i)))*dy2i
flz2 = (vzr2(l)*(f(l,k,j,i)+f(l,k+2,j,i))-vzl2(l)*(f(l,k,j,i)+f(l,k-2,j,i)))*dz2i
flv2 = (vvr2(l)*(f(l,k,j,i)+f(l+2,k,j,i))-vvl2(l)*(f(l,k,j,i)+f(l-2,k,j,i)))*dv2i
df(l,k,j,i)=-(cc1*(flx+fly+flz+flv)-cc2*(flx2+fly2+flz2+flv2))
enddo
enddo
enddo
enddo
図1:GT5Dにおける4次元差分カーネルのサンプルコード
| npx × npy | 1×16 | 2×8 | 4×4 | 8×2 | 16×1 |
| x通信量(MB) | - | 3.93 | 7.86 | 15.73 | 31.46 |
| y通信量(MB) | 31.46 | 15.73 | 7.86 | 3.93 | - |
| 京(差分) | 1.00 | 1.19 | 1.84 | 1.50 | 1.09 |
| 京(通信) | 1.00 | 0.67 | 0.57 | 0.67 | 1.02 |
| BX900(差分) | 1.00 | 0.97 | 0.98 | 1.02 | 0.95 |
| BX900(通信) | 1.00 | 0.68 | 0.60 | 0.72 | 1.02 |
表1: 4次元差分カーネル(問題サイズ(Nx,Ny,Nz,Nv)=(240,240,64,128))を2次元領域分割によるハイブリッド並列処理16MPI×8OpenMPで処理した際に得られた処理時間のx,y方向の並列数依存性。1×16の処理性能を1として規格化した。
このカーネルコードに対して、「京」(SPARC64VIIIfx)とBX900(Nehalem-EP)において2次元領域分割の並列数の設定条件を変化させて差分計算と通信処理の性能を測定した結果を表1に示す。まず、通信処理に関してはx,y方向の並列度を変化させると袖領域データの通信量が変化し、これに比例して通信コストが変化することがわかる。領域分割した際の相対的な計算コストと通信コストは1プロセスの担当領域の体積と表面積に比例するため、2次元であれば正方形、3次元であれば直方体に近い領域形状を選ぶことで通信コストを最小化できる。
一方、差分計算の演算量は領域形状に依存しないにも関らず「京」では処理コストが領域形状に極めて強く依存する。この結果、通信量の観点からは最適な並列度となるnpx×npy=4×4で処理速度が低下するという結果が得られた。この依存性はBX900ではほとんど見られないことから「京」特有の問題であることがわかった。ハードウェア機構の観点からは「京」に搭載されているSPARC64VIIIfxプロセッサとBX900に搭載されているNehalem-EPプロセッサではL1キャッシュのway数が2および8と大きく異なることから、L1キャッシュ競合の観点から「京」における性能調査を実施した。
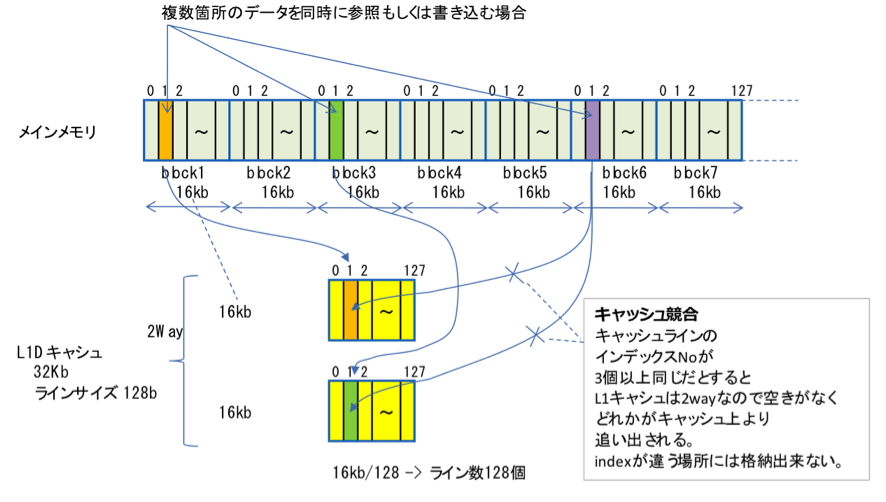
図2:「京」におけるL1キャッシュ競合の説明。メモリ空間はblock単位で管理され、1blockは128Byteのキャッシュライン128個で構成される。
図2にL1キャッシュとメインメモリ上のデータ配置の関係を示す。「京」におけるL1キャッシュは2wayの構成となり、1wayに16,384Byte(128Byteのキャッシュライン128個)が含まれる。メインメモリ上でも1wayのデータサイズと同じ16,384Byte毎のblockによってデータが管理され、各キャッシュラインはインデックスに従って、常にL1キャッシュのway上の同じ位置にロードされる。このため複数のデータを参照する演算処理において同じインデックスをもつキャッシュラインをway数以上同時に参照する場合にデータをロードするway数が不足してL1キャッシュ競合が発生し、データの再ロードが必要となる。従って、8wayのL1キャッシュをもつBX900に比べて2wayのL1キャッシュをもつ「京」はL1キャッシュ競合の確率が大幅に高くなる。
| data | address | address/16384 | block index | line index |
| f(l-2, k, j, i) | 16785408 | 1024.50 | 1024 | 64 |
| f(l-1, k, j, i) | 16785416 | 1024.50 | 1024 | 64 |
| f(l, k, j, i) | 16785424 | 1024.50 | 1024 | 64 |
| f(l+1, k, j, i) | 16785432 | 1024.50 | 1024 | 64 |
| f(l+2, k, j, i) | 16785440 | 1024.50 | 1024 | 64 |
| f(l, k-2, j, i) | 16783312 | 1024.37 | 1024 | 47 |
| f(l, k-1, j, i) | 16784368 | 1024.44 | 1024 | 55 |
| f(l, k+1, j, i) | 16786480 | 1024.57 | 1024 | 72 |
| f(l, k+2, j, i) | 16787536 | 1024.63 | 1024 | 80 |
| f(l, k, j-2, i) | 16641808 | 1015.74 | 1015 | 94 |
| f(l, k, j-1, i) | 16713616 | 1020.12 | 1020 | 15 |
| f(l, k, j+1, i) | 16857232 | 1028.88 | 1028 | 113 |
| f(l, k, j+2, i) | 16929040 | 1033.27 | 1033 | 34 |
| f(l, k, j, i-2) | 7594000 | 463.50 | 463 | 64 |
| f(l, k, j, i-1) | 12189712 | 744.00 | 744 | 0 |
| f(l, k, j, i+1) | 21381136 | 1305.00 | 1305 | 0 |
| f(l, k, j, i+2) | 25976848 | 1585.50 | 1585 | 64 |
表2:図1の4次元差分カーネルで使用するデータのメモリアドレス計算例。表1におけるnpx×npy=4×4の場合。f(l,k,j,i)のアドレスはl=k=j=i=1の場合にFujitsu Fortranの組み込み関数であるLOC関数で取得したアドレスを示し、残りのアドレスはそこから各方向のインデックスに従って計算したアドレスを示す。blockとlineの構成は図2を参照。
図1で示した4次元差分カーネルにおけるL1キャッシュ競合の状況を確認するために、参照する4次元配列f(l,k,j,i)のメモリアドレスを計算し、各参照データのラインインデックスを計算した。ここで、表2は表1で最も悪い結果を示したnpx×npy=4×4の例を示している。まず、l方向のインデックスが異なるf(l-2,k,j,i) ~ f(l+2,k,j,i)が同じラインインデックスをもつが、これらのデータは同じキャッシュライン上に存在するためL1キャッシュ競合の問題はない。一方、f(l,k,j,i+2)とf(l,k,j,i-2)はブロックインデックスが異なるが、f(l-2,k,j,i) ~ f(l+2,k,j,i)と同じラインインデックスに格納されており、L1キャッシュの競合を引き起こす。この状況はメモリアドレスをwayサイズである16,384Byteで割った値(address/way)がi-2 ~ i+2で0.5ずつ増加する、すなわち、iとi+2のメモリアドレスのストライド(2×(ny+4)×(nz+4)×(nv+4)×8Byte)がwayサイズで完全に割り切れることからもわかる。このようなL1キャッシュ競合を回避するには差分計算で参照するメモリアドレスのストライドをwayサイズで割った値の端数(address/way)が0、あるいは、1/2、1/3…とならない配列形状を選択する必用がある。この状況はベクトルマシンにおけるバンクコンフリクトの問題に似ており、回避策についてもバンクコンフリクトを回避するための常套手段となっている配列のパディングが有効である。
| np | 0 | 1 | 2 | 3 | 4 | 5 |
| i方向のストライド(nv+4+np)×(nz+4)×(ny+4)/way | 544.50 | 548.63 | 552.75 | 556.88 | 561.00 | 565.13 |
| j方向のストライド(nv+4+np)×(nz+4)/way | 8.51 | 8.57 | 8.64 | 8.70 | 8.77 | 8.83 |
| 京(差分) | 1.85 | 1.00 | 1.10 | 1.02 | 3.82 | 1.03 |
表3:表1におけるnpx×npy=4×4の場合を対象としたパディングによる性能改善。パディング量npを変化させると配列のストライド、および、性能が変化する。
図1の4次元差分カーネルにパディングを適用して修正したカーネルによって得られた処理性能データを表3に示す。修正カーネルでは配列fの宣言をf(-1:nv+2,-1:nz+2,-1:ny+2,-1:nx+2)からf(-1:nv+2+np,-1:nz+2,-1:ny+2,-1:nx+2)に修正して1次元目(l方向)の配列サイズをパディング量npだけ余分に増やし、5点差分で参照されるデータのメモリアドレスのストライドを変更することによってL1キャッシュ競合の状況の改善を試みた。ただし、表2の例で示すようにl方向とk方向のデータは同じblock上に格納されてキャッシュ競合を考慮する必要はないので、ここではi方向とj方向のストライドを示している。結果を見てわかるように、差分計算の処理性能はi方向のストライド数をwayサイズで割った値の端数が1/2、0となるnp=0、np=4で極端に悪化するが、np=1ではnp=0に比べて約8割の性能改善が確認できる。このようにパディング量を調整することによって表1の比較における最速の1×16の場合と同程度に差分計算の性能を改善できることがわかった。L1キャッシュ競合の有無を判断するには表2のようなアドレス計算が必要となるが、配列形状によって決まるメモリアドレスのストライド数をwayサイズで割った値の端数がL1キャッシュ競合を回避するための簡易的な指標となることがわかった。以上の手法は1つの配列内でのキャッシュ競合を検出する手法として有効であるが、複数の配列を用いる場合には配列間のキャッシュ競合を検出することが難しい。このような場合には、Fujitsu Fortranの組み込み関数として提供されているLOC関数[2]でメモリアドレスを取得してL1キャッシュ競合の有無を確認する必用がある。
問い合わせ先
idomura.yasuhiro_at_jaea.go.jp (_at_はアットマークに置換してください)
参考文献
[1] Y.Idomura et al., Comput. Phys. Commun 179, 391-403 (2008).
[2] Parallelnavi for MP10 V1.0 Fortran文法書