OpenMPを用いたMPI通信隠蔽手法による並列化FFTの高速化
ソフトウェア
ものづくり > 流体解析 > GKVそのほかの分類
高速化手法概要
「京」を用いて大規模問題を解析する上で、並列数に対する処理性能のスケーリングを向上することが必要となる。特に、解析を高速化して処理時間を短縮する、あるいは、より長時間スケールの問題を取り扱う上では、問題規模を固定して並列数を増大する強スケーリングの向上が重要な課題となる。しかしながら、強スケーリングでは並列数が大きくなると演算に比べて通信のコストが相対的に増加するため、通信処理がボトルネックとなる。ここでは、OpenMPを用いたMPI通信隠蔽手法を紹介するとともに、重いデータ転置通信を含む並列化FFT(高速フーリエ変換)の強スケーリングを向上する適用事例を示す。
計算モデル
OpenMPとMPIを用いたハイブリッド並列プログラムによる並列処理を想定する。MPI通信隠蔽を行わない場合は、あるスレッドがMPI通信を行う間(図1ではcall MPI_commun)、他のスレッドは待ち状態となる。そして、通信完了後、全てのスレッドで同時に演算に取りかかる(図1ではcall indep_comput)。このように、従来の手法では通信中の演算コア、および、演算中の通信帯域が活用されておらずアイドル状態にある。通信隠蔽、あるいは、通信と演算のオーバーラップではこの無駄なリソースを活用することで処理の高速化を図る。
OpenMPを用いてMPI通信の隠蔽を行う場合は、演算処理を該当する通信データを利用するものと利用しないものに分類し、後者をMPI通信と同時に処理する。図3に3次元データに並列化2次元FFTを適用する場合の模式図を示す。通常の処理では(X,Y)方向にデータ転置通信を行なってデータ分割軸の切り直しを行ってから各方向にFFT処理を適用するが、図3ではZ方向に異なる位置のデータに対するデータ転置通信とFFT処理にデータ依存関係が無いことに着目し、これらの通信と演算をオーバーラップする。具体的な実装のイメージを図2に示すが、まず、MASTER指示構文(あるいはSINGLE指示構文)により通信スレッドを指定し、その他のスレッドは通信データを利用しない演算を同時に処理する。この際、演算処理のdoループ分割はDYNAMICとし、動的負荷分散によって演算処理を通信スレッド以外のスレッドに振り分け、通信終了後は通信スレッドを演算に復帰させる。また、演算が複数のdoループから構成される場合には、!$OMP END DOの指示文を用いると、暗黙にスレッド間のバリア同期が含まれるため通信スレッドと同期がとられてしまう。そこで、NOWAIT指示句を挿入することで、不必要なバリア同期を避けることができる(※1)。最後に、通信データが利用される前に!$OMP END DOの指示文による同期処理、あるいは、!$OMP BARRIER指示文による明示的な同期処理を行い、通信完了後に通信データを利用する演算を実行する。以上の処理によって、従来の手法では使われていなかった演算コアと通信帯域をフルに活用して通信処理のオーバーヘッドを抑制することが可能となる。
図1、2より、通信と演算のオーバーラップを用いた処理時間の見積もりが算出できる。図1においてNをOpenMPスレッド数、通信隠蔽を行わない場合の通信時間をT、 演算時間をCとすると、総演算コストはNC、経過時間はC+Tである。一方、図2の通信隠蔽を行う場合は、(N-1)T分の演算が通信と同時に処理され、NC-(N-1)T分の演算が通信完了後に処理される。この結果、全処理時間の理論推定値はC+T/Nとなる(※2)。このことは、MPI通信が演算によって十分に隠蔽された場合、MPI通信コストをスレッド数分の一まで削減できることを示している。
※1ただし、NOWAIT指示句を挿入すると、必ずしもコーディング通りの演算順序を保証しないので注意が必要である。例えば、図2の例ではdoループが一つだけだが、複数のdoループを同時にNOWAIT指示句を用いて並列化する場合を考える。この場合、あるループの実行途中でも、先に担当分の演算を終えた他のスレッドは次のループの計算を開始してしまう。そのため、複数のdoループの間に依存関係がないように配慮する必要がある。
※2ただし、この見積はT<NC/(N-1)のとき、すなわち、通信隠蔽に十分な演算処理が存在する場合を考えており、さらに、ロードインバランスによる処理時間の増加等は無視している。

図1:MPI通信隠蔽を行わない場合の疑似コード(Fortranベース)と動作の模式図。
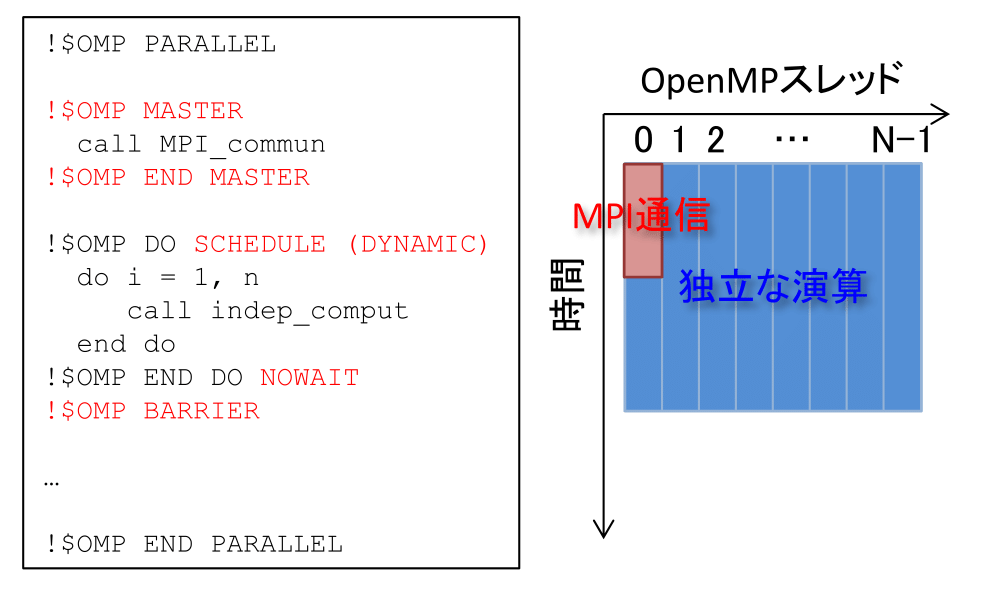
図2:MPI通信隠蔽を行った場合の疑似コード(Fortranベース)と動作の模式図。
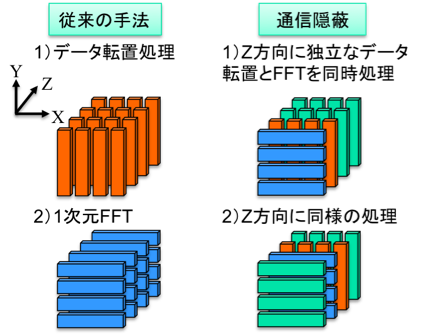
図3:3次元データにおける2次元並列化FFTを適用する場合の模式図。
適用事例
プラズマ乱流シミュレーションコードGKV[1]の高速化のためにMPI通信隠蔽手法を適用した[2]。GKVでは5次元空間(x,y,z,v,w)におけるプラズマのダイナミクスを差分法・スペクトル法を併用して解く。この際に、(x,y)方向のみをスペクトル方で取り扱うため、図3の模式図のように2次元FFTを他の次元のグリッド数分だけ複数回処理する。以下では、(X,Y)方向の並列2次元FFTを1次元FFTと転置通信(MPI_ALLTOALL)を利用して実装し、Z方向(実際には(z,v,w)方向)に複数回の処理を行う事例を考える。並列2次元FFTにおいて、1次元FFTと転置通信はデータ依存関係があり非可換であるが、Z方向にインデックスの異なる複数の並列2次元FFTをパイプライン化して処理することで1次元FFTと転置通信のオーバーラップを行う。
計算条件
実行環境:PRIMEHPC FX10(東京大学 Oakleaf-FX)
プログラミング言語:Fortran
コンパイラ:富士通社製クロスコンパイラ(mpifrtpx)
コンパイルオプション:-Kfast,openmp
FFTライブラリ:FFTW3
計算規模:格子点数512×512、2048組の2次元スペクトル法演算(計算の流れとしては、並列2次元倍精度複素実FFT→実空間での積和演算→並列2次元倍精度実複素FFT)
並列化:FFTを適用する2次元空間をTranspose-split法で並列化。
並列数:1ノード当たり1 MPIプロセス・16 OpenMPスレッドで固定し、ノード数を4から64まで(コア数にして64から1024まで)変化させた場合の強スケーリング性能を調べる。
計算結果
図4の処理時間の比較から分かる通り、通信と演算のオーバーラップを行うことで、MPI通信時間が実質的に隠蔽され、処理時間が短縮されている。前節で議論されたオーバーラップ時の処理時間の理論推定値C+T/Nが良い見積もりを与えることが確認できる。また、図5に示す加速率の推移から、オーバーラップにより並列処理のスケーラビリティが向上していることが見て取れる。さらにオーバーラップによる高速化率(図6)を見ると、ばらつきはあるものの、今回計測した範囲ではMPIプロセスを増大させていくほどにオーバーラップの効果が増大していくことが分かる。これは、並列数が高いほど計算全体に占める通信の割合が増えていくためである。以上から、OpenMPを用いたMPI通信隠蔽手法が並列処理の高速化に効果的であるという結果が得られた。特に、今回のような通信スレッドを用いたオーバーラップ手法は、非同期MPI通信だけでなくMPI_ALLTOALLのような同期MPI通信に対しても有効であることが確認された。

図3. MPIプロセス数に対する処理時間の推移。オーバーラップ時の理論推定値は、オーバーラップなしの通信時間T、演算時間C、スレッド数NとしてC+T/Nにより算出。
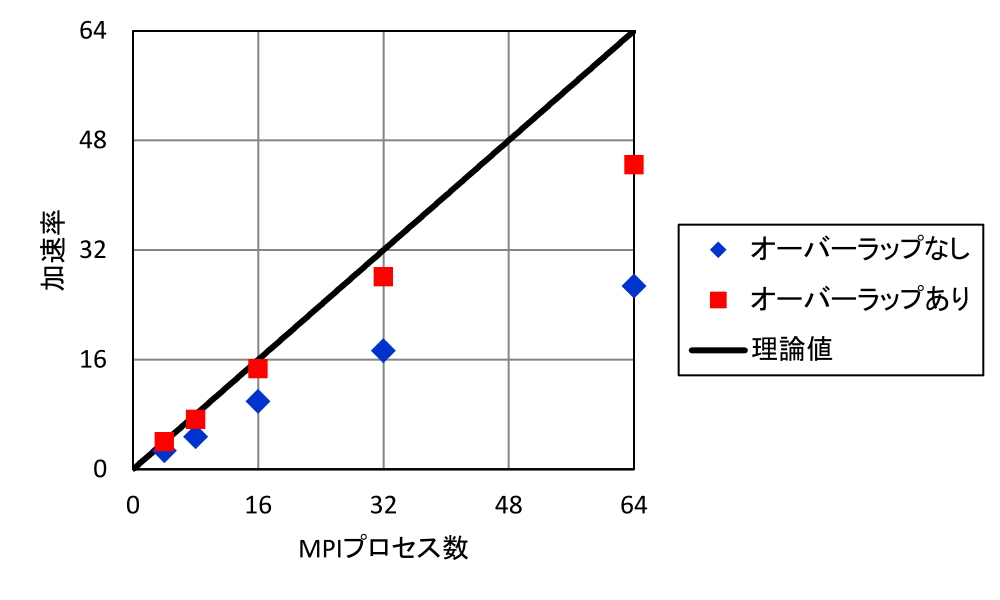
図4. MPIプロセス数に対する加速率(=処理速度/並列化しない場合の処理速度)の推移。理想加速率はオーバーラップありの場合の4 MPIプロセスでの処理速度を基準として表示。
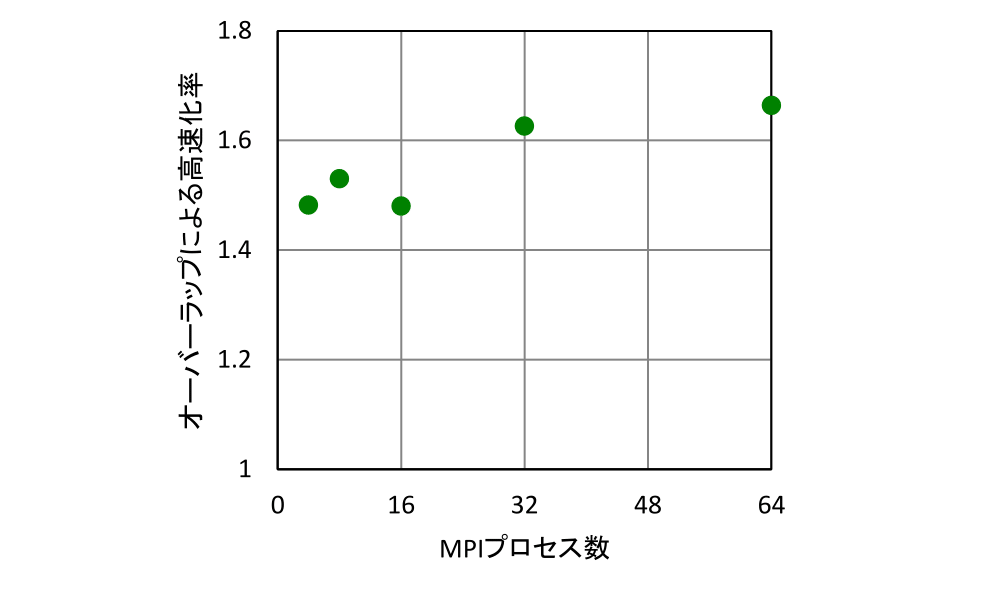
図5. MPIプロセス数に対するオーバーラップによる高速化率(=オーバーラップありの処理速度/オーバーラップなしの処理速度)の推移。
問い合わせ先
idomura.yasuhiro_at_jaea.go.jp (_at_はアットマークに置換してください)
参考文献
[1] T.-H. Watanabe and H. Sugama, Nucl. Fusion 46, 24 (2006).
[2] S. Maeyama et al., Plasma Fusion Res. 8, 1403150 (2013).